Intel今天在AI Summit 2019活動上,揭露AI生態系的最新佈局。除了發表新一代的Movidius視覺運算處理器(VPU)Keem Bay,要搶進邊緣運算的市場,也在與VPU搭配的軟體工具集OpenVINO中,新增了DevCloud硬體部署測試平臺,讓企業能直接從雲端上傳訓練好的模型,來測試出最適合該模型的硬體設施,此外,也宣布成立Edge AI NanoDegree,來培育AI領域中的邊緣運算人才。
VPU(Vision Processing Unit)是Intel 2016年併購Movidius後,所推出專門進行影像識別的處理器。而新一代的VPU Keem Bay,是繼2016年推出首款VPU Myriad 2、2017年推出VPU Myriad X後,專門為IoT邊緣運算所設計的第三代VPU,能處理的資料已經不侷限於影像識別,現在連語音、社群媒體中的用戶行為等邊緣端的非結構化資料,都能用Keem Bay來進行推論(Inference)。
Intel副總裁暨AI產品部總經理Naveen Rao表示,Keem Bay的推論效能(performance)為同類產品Nvidia TX2的4倍,也是華為Ascend 310的1.25倍,雖然比不上Nvidia另一款旗艦產品Xavier,但在相差不多的表現下,Keem Bay的功耗只有30瓦,約為Xavier的五分之一,「功耗會是一個關鍵,雖然高效能運算很重要,但客戶也很在意能源的耗費。」
若從能源的角度來看,在耗能固定的效能表現上,Naveen Rao更宣稱,Keem Bay的效能足足是Nvidia TX2的6.2倍,若去測量處理器每平方毫米的每秒效能表現,Keem Bay更能達到Nvidia TX2的8.7倍,「而且,如果再搭配上OpenVINO軟體來最佳化模型,效能初步能再提高50%,而且我們還會繼續優化軟體堆疊架構。」

至於,Intel是如何達到這個成果?Intel IoT部門副總裁Jonathan Ballon表示,用VPU搭配CPU執行運算時,在CPU的部分,Intel正在用64位元記憶體頻寬(memory bandwidth)來加快資料傳輸,同時也改良指令集來提高推論效率,而且,為了達到工作負載平衡,CPU也執行平行運算,且自動將推論工作轉移到加速卡上,來更有效的利用運算資源。
而在軟體層面,Keem Bay也結合OpenVINO工具集來優化AI模型。當客戶要將模型部署到VPU上,編譯器可支援TensorFlow、Pytorch、MXNet、Keras、Caffe、ONNX等深度學習框架,且龐大神經網絡也能透過模型優化器(model optimizer),在不影響辨識準確度的前提下進行壓縮,來減少運算資源的消耗。
比如提供醫療影像辨識平臺AIRX的Go Healthcare這家公司,就是用Intel的OpenVINO來最佳化模型,優化前後的影像處理延遲情形從2.86降至0.66秒,也就意味著,系統能在相同時間內標注更多的病灶影像,來加速影像辨識的流程。
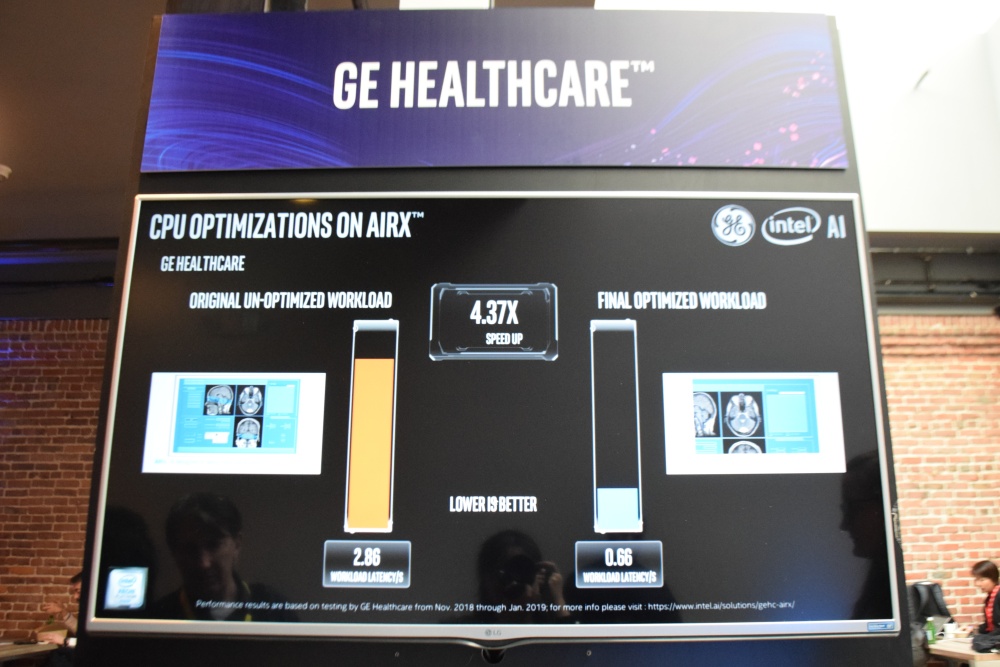
用Intel的OpenVINO來優化模型後,優化前後的影像處理延遲情形從2.86降至0.66秒,快了4.37倍。
Keen Bay預計在2020上半年將正式推出Keem Bay,Intel IoT部門副總裁Jonathan Ballon受訪時,雖無正面回應市場定價,不過以GPU作為比價對象:「Keem Bay的價格將會是GPU的一部分而已(a small fraction of the price of a comparable GPU)。」加上發表會上公布的圖表數據,不難發現Intel將Nvidia視為競爭對手。
Intel推出硬體部署測試平臺DevCloud,讓客戶部署模型更容易
除了硬體VPU處理器的發表,為了讓客戶不再困擾該使用哪種硬體處理器, Intel今天也發布了「DevCloud硬體部署測試平臺」,是OpenVINO的軟體工具集的新功能。這個平臺能讓客戶上傳演算法,並選擇不同的處理器來測試軟硬體搭配的效能,來找到最合適部署的硬體。「過去的幾個月中,DevCloud在進行Beta版測試,如今已經有2700多家客戶使用過。」Jonathan Ballon表示。
該平臺的使用方法分為兩步驟,第一,是上傳演算法並選擇硬體處理器,包括CPU、FPGA、VPU等邊緣運算用的推論晶片,在大方向的選定硬體類別後,即可在雲端執行推論,並得到推論的速度與成效;接著,重複測試幾次並選定了要使用的硬體類型後,就能更進一步選擇處理器型號、要搭配哪種加速卡、batch-size與執行緒的數量等,來進行更精確的測試。
.JPG)
在OpenVINO工具集中,除了具備模型最佳化的功能(model optimizer),也新增了邊緣運算硬體部署最佳化的功能(Edge AI Optimizer)。

第一步,先上傳演算法並選擇硬體處理器類別進行測試。

第二,能更進一步選擇處理器型號、要搭配哪種加速卡、batch-size與執行緒的數量等,來進行更精確的測試。
測試完成後,下一步驟就是部署。Jonathan Ballon表示,邊緣運算的應用不是只要建構一個解決方案,而是需要大規模的將軟體部署到邊緣端產品中,而Intel的優勢在於其CPU搭配加速卡的組合,「效能比只用GPU高很多,」再加上軟體平臺的工具以及系統整合商的資源,能創造出一個完整的AI生態系,讓客戶直接在其中找到合作夥伴,更容易進行大規模產品部署。
要發展生態系,Intel長期以來也提供開發者許多學習資源來培育AI人才。2016年底,Intel因應AI趨勢來襲而成立了Nervana AI學院,以Intel AI相關軟硬體為教材來提供線上課程。「不過,以往我們有關AI的教育和培訓都針對雲端開發人員,現在我們也要培訓開發人員在邊緣端應用AI。」Jonathan Ballon表示,Intel宣布成立具有Udacity學位的Edge AI NanoDegree,來因應邊緣運算興起的趨勢,也釋出獎學金來鼓勵女性參加。